
The AI World Just Got Turned Upside Down. LITERALLY.
Alright fam, drop whatever you’re doing. The AI arms race? The whole “bigger is better” mantra we’ve been fed for years? FORGET IT. It’s over. Liquid AI just dropped a nuke on the whole paradigm, and it’s called Liquid Nanos.
So, what are they? In simple terms, Liquid Nanos are a new family of extremely tiny, task-specific models. But that’s the boring explanation. The REAL story is that these models run DIRECTLY on your phone, your laptop, your car, your smart toaster… whatever. NO cloud. NO latency. NO sending your private data to some server farm in who-knows-where. This is AI that lives with YOU.
And when I say tiny, I mean it. These models range from a featherweight 350M to just 2.6B parameters. For context, that’s hundreds of times smaller than the big boys. But here’s the part that will break your brain: they’re delivering GPT-4o-class performance on key tasks while running directly on phones, laptops, cars, embedded devices, and GPUs with the lowest latency and fastest generation speed. Yes, you read that right. I’ll say it again. GPT-4o level results, from a model small enough to run on your phone. Let that sink in.
This isn’t just another model release; it’s a fundamental paradigm shift. For years, powerful AI meant being tethered to the cloud, dealing with API costs, and worrying about privacy. Liquid Nanos cut that cord. They are “specifically designed for edge AI and on-device deployment,” which means the power of frontier AI is no longer locked away in datacenters.
Think about what this unlocks. It’s a massive democratization of agentic AI. When you don’t need a venture capitalist’s bankroll to pay for cloud compute, suddenly individual developers, startups, and even hobbyists can build applications that were previously impossible. The economic and infrastructural barriers to building world-class AI have been shattered.
But it goes deeper. On-device AI means the model can access and process your personal data your emails, your documents, your messages without that data EVER leaving your device. This solves the single biggest hurdle for creating truly personalized assistants: the privacy trade-off. An AI that can understand the full context of your life on your device can be infinitely more helpful than a cloud-based one you’re hesitant to share data with. This is the birth of genuinely personal AI, because it is genuinely private.
Small Size, GIGANTIC Performance. The Proof is in the Pixels.
Okay, okay, I hear you. “GPT-4o performance? On my phone? Show me the proof!” Bet. Let’s break down the charts. No marketing fluff, just pure, unadulterated data. And trust me, it’s SPICY. 🔥
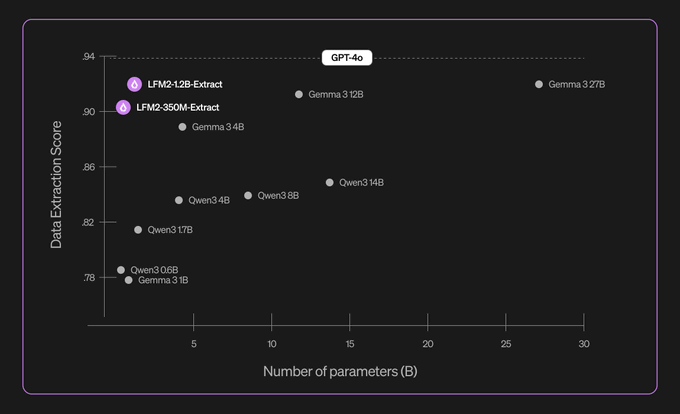
Data Extraction: The Tiny Giant
First up, data extraction. This is the crucial task of pulling structured info (like JSON) from messy, unstructured text (like an email).
LOOK AT THIS. Our little 1.2B parameter hero, LFM2-1.2B-Extract, is standing shoulder-to-shoulder with the GPT-4o baseline, scoring over 0.9 on the Data Extraction Score. And see that Gemma 3 27B model way over on the right? That’s the heavyweight champion everyone’s afraid of. And our Nano is basically matching its performance while being 22.5x SMALLER. This isn’t a fair fight; it’s an ambush. Even the tiny LFM2-350M-Extract is out there schooling models many times its size, like Gemma 3 4B and Qwen3 4B.
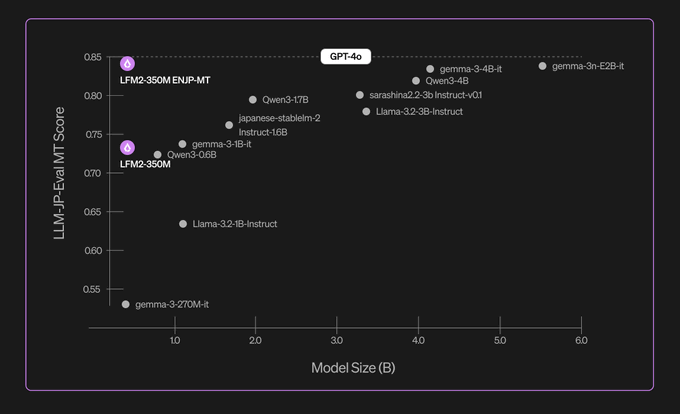
Translation: The Pocket Polyglot
Think a tiny 350M model can’t handle complex, nuanced language translation? WRONG.
The chart shows the LLM-JP-Eval MT Score for English-Japanese translation, a notoriously difficult task. The LFM2-350M-ENJP-MT model clocks in with a score around 0.84, absolutely smoking models like Qwen3-1.7B and Llama-3.2-3B-Instruct. It’s even competitive with models 10 times its size. For real-time, on-device translation? This is an absolute game-changer. No more awkward Google Translate moments when you have no internet in the middle of Shibuya Crossing.
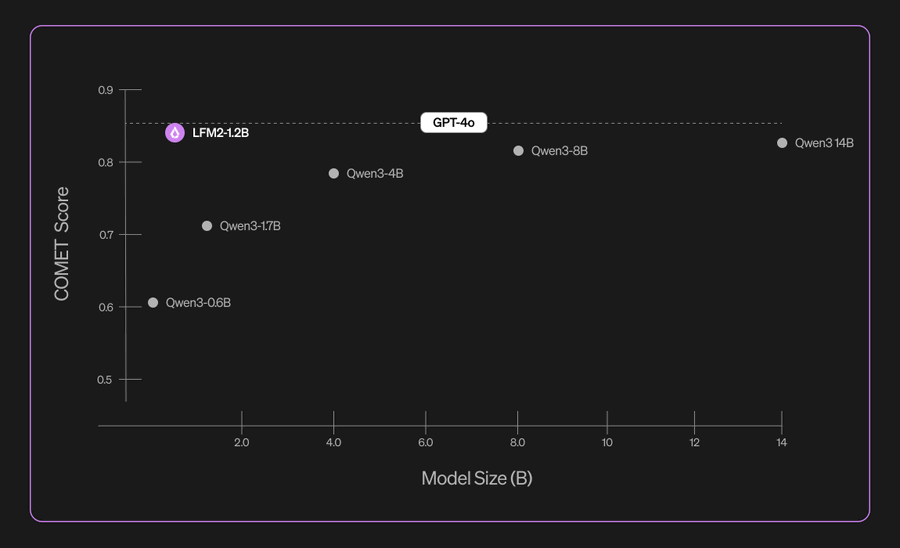
General Performance: Playing in the Big Leagues
So, it’s a specialist. But how does it stack up on general benchmarks?
This chart shows the COMET Score, a general measure of quality. The LFM2-1.2B scores around 0.84, just a hair below the GPT-4o baseline but clearly outperforming much larger models like Qwen3-4B and even Qwen3-17B.
Now, let’s be real. Is it going to beat GPT-4o at writing a Shakespearean sonnet about your dog? Maybe not. That’s not the point. The point is that it’s PLAYING IN THE SAME LEAGUE. It’s achieving near-frontier performance on critical tasks, in a package that fits in your pocket. This isn’t about winning every single benchmark; it’s about insane efficiency.
What these charts reveal is a deliberate strategy. Liquid AI isn’t trying to beat GPT-4o at its own game of general intelligence. They are redefining the game entirely. They are proving that a collection of small, specialized, hyper-efficient models can deliver more practical value for real-world applications than one monolithic, resource-hungry giant. It’s a shift from a “one model to rule them all” philosophy to a “right tool for the job” philosophy. And it’s brilliant.
The Secret Sauce: What the Heck is the LFM2 Architecture?
So how is this even possible? Is it black magic? Did they make a deal with the devil? Almost. They built a completely new kind of AI brain. Let’s pop the hood on the LFM2 architecture.
The Hybrid Brain – Not Your Standard Transformer
This isn’t your grandpa’s Transformer model. LFM2 is a “new hybrid Liquid model with multiplicative gates and short convolutions”. The whole thing is built from 16 blocks: 10 of these are “double-gated short-range convolution blocks” and 6 are blocks of “grouped query attention” (GQA).
Think of it like this: regular Transformers are all about ‘attention,’ which is great for seeing the whole picture (long-range dependencies). But it’s computationally expensive as hell. LFM2 is a hybrid. It uses super-efficient convolutions to handle the local details, like understanding the relationship between words right next to each other, and saves the expensive ‘attention’ mechanism for when it really needs to connect ideas across a long document. It’s the best of both worlds: lightning fast and contextually aware.
The REAL Magic – LIV and STAR
This is where it gets WILD. The architecture itself wasn’t just designed by humans; it was discovered by Liquid AI’s proprietary “STAR engine,” a neural architecture search system that’s basically an AI that designs other AIs. It’s one job is to find the absolute perfect balance of quality, memory usage, and speed for edge devices.
The core innovation it found is something called “Linear Input-Varying (LIV) operators”. Get this: instead of having fixed weights like a normal neural network, the model dynamically generates the right weights for the specific problem it’s looking at, in real-time. It’s not just processing data; it’s reconfiguring its own brain on the fly to be the perfect tool for that exact moment. INSANE.
The Training Regimen – Forging a Genius
You can have a genius brain, but you still need a world-class education. Liquid AI’s training process is a masterclass. It starts with knowledge distillation, where a bigger, wiser model (LFM1-7B) acts as a “teacher,” pouring all its knowledge into the smaller Nano. Then, they put it through an intense bootcamp of large-scale Supervised Fine-Tuning (SFT), a custom version of Direct Preference Optimization (DPO), and iterative model merging to lock in the performance. The result is a tiny model with the wisdom of a giant.
This entire system the faster architecture, the AI-driven design process, and the advanced training techniques creates a self-reinforcing flywheel of efficiency. The architecture is 3x faster to train than the previous generation, which means they can iterate more quickly. The STAR engine ensures future architectures will be even better. This isn’t a one-time achievement; Liquid AI has built a revolutionary assembly line for producing hyper-efficient AI.
Meet the Nano Family: Your New Task-Specific Superheroes 🦸
Okay, theory is cool, but what can you actually DO with these things? Liquid AI has launched an initial squad of Nanos, each one a specialist, a superhero for a specific task. Let’s meet the team.
| Liquid Nano Model | Size | Primary Task | Killer Use Case (Creator-Style) |
| LFM2-Extract | 350M / 1.2B | Structured Data Extraction | The Data Wizard: Turns your messy pile of invoice emails into perfectly clean JSON. No more manual data entry! |
| LFM2‑350M‑ENJP‑MT | 350M | English ↔ Japanese Translation | The Pocket Translator: Real-time, offline Japanese translation on your phone. Perfect for your next trip to Tokyo. |
| LFM2‑1.2B‑RAG | 1.2B | Retrieval-Augmented Generation | The Knowledge Guru: Build a chatbot for your docs that gives answers based on facts, not hallucinations. |
| LFM2‑1.2B‑Tool | 1.2B | Function Calling / Tool Use | The Agentic Workhorse: Create on-device agents that can actually do stuff like book appointments or control your smart home. |
| LFM2‑350M‑Math | 350M | Mathematical Reasoning | The Pocket Mathematician: A tiny model that can solve tricky math problems right inside your calculator app. |
The LFM2-Extract models are particularly impressive, with support for English, Arabic, Chinese, French, German, Japanese, Korean, Portuguese, and Spanish, and the ability to output to JSON, XML, or YAML. Pro tip from the Liquid team: provide a schema template in the system prompt for even better accuracy on complex documents.The LFM2-1.2B-RAG model is also a beast, having been fine-tuned on over a million samples of multi-turn, multi-document conversations to make it incredibly robust for complex Q&A.
Notice a pattern here? Data Extraction (Perception), RAG (Grounded Knowledge), Tool Use (Action), Math (Reasoning), Translation (Communication). These aren’t just random tasks. They are the fundamental building blocks the “primitives” of an autonomous AI agent. Liquid AI isn’t just giving us cool toys; they’re giving us an “agent starter pack” to build the next generation of intelligent, on-device applications.
ENOUGH TALK. Let’s Get Our Hands Dirty! (Copy-Paste Ready Code)
Theory is done. Hype is high. Time to write some code. NO FLUFF. Here are the copy-paste-ready commands to get these Nanos running on your own machine. Let’s GOOOO! 🚀
Step 0: The Setup – Dead Simple.
Open your terminal and get the essentials.
pip install -U transformers torch accelerate
Method 1: Running with Hugging Face Transformers (The Standard Way)
This is the easiest way for most people to get started. It’s clean, simple, and uses the library you already know and love.
# Let's get this running!
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Pick your Nano! We'll use the 2.6B base model for this example.
model_id = "LiquidAI/LFM2-2.6B" # Or "LiquidAI/LFM2-1.2B", etc.
print("Loading model and tokenizer... this might take a sec.")
# Using bfloat16 for speed and efficiency.
model = AutoModelForCausalLM.from_pretrained(
model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
# attn_implementation="flash_attention_2" # <-- UNCOMMENT ON A COMPATIBLE GPU (NVIDIA Ampere+)
)
tokenizer = AutoTokenizer.from_pretrained(model_id)
print("Model loaded! Let's cook.")
# The prompt - using the official ChatML-like template
prompt = "What is C. elegans, and why is it important in biology?"
messages = [{"role": "user", "content": prompt}]
# Apply the template - this formats the input correctly for the model
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
# GENERATE!
# These are the recommended params from the Liquid AI team [9]
output = model.generate(
input_ids,
do_sample=True,
temperature=0.3,
min_p=0.15,
repetition_penalty=1.05,
max_new_tokens=512,
)
# Decode and print the response
response = tokenizer.decode(output, skip_special_tokens=False)
print("\n--- MODEL RESPONSE ---")
print(response)
Method 2: High-Throughput with vLLM (For Power Users)
Need to run a TON of inferences? Batch processing? vLLM is your best friend for maximum throughput.
# For when you need SERIOUS speed.
# First: pip install vllm
from vllm import LLM, SamplingParams
# List of prompts to process in a batch
prompts =
# Use the same recommended sampling params
sampling_params = SamplingParams(temperature=0.3, min_p=0.15, repetition_penalty=1.05, max_tokens=512)
# Load the model with vLLM - let's use the RAG model!
llm = LLM(model="LiquidAI/LFM2-1.2B-RAG")
# Generate responses for all prompts at once
outputs = llm.generate(prompts, sampling_params)
# Print the results
for output in outputs:
prompt = output.prompt
generated_text = output.outputs.text
print(f"Prompt: {prompt!r}")
print(f"Generated text: {generated_text!r}\n---")Method 3: On Your Laptop CPU with llama.cpp (The Ultimate Edge)
No GPU? NO PROBLEM. These models were born for the CPU. Thanks to first-class llama.cpp support, you can run this on almost any modern laptop. Just head over to the LiquidAI Hugging Face page, grab the GGUF checkpoints for the model you want, and follow the standard llama.cpp instructions. This is the ultimate proof of on-device power.
By embracing open standards like Transformers, vLLM, and llama.cpp, Liquid AI made a brilliant move. They’re not locking you into a proprietary ecosystem. They’re making it as easy as possible for the entire community to adopt, experiment, and build, which will accelerate innovation at a blistering pace.
Why This is a GAME CHANGER for Every Dev Out There.
Okay, so the tech is cool, and you can run it. But what does this mean? Why is this more than just another model release? Because the biggest names in tech are already on board, and they see the future.
Just listen to what the titans of industry are saying:
- Mikhail Parakhin, the CTO of Shopify, finds it “very impressive that Liquid’s novel… technique enables their fast and small LLMs to perform on par with frontier models such as GPT-4o.” He’s excited to use their models across Shopify’s platforms. Think faster, smarter, on-device shopping assistants that protect your privacy.
- Ranjit Bawa, the Chief Strategy and Technology Officer at Deloitte U.S., is excited about the “opportunity to collaborate with Liquid AI,” seeing the potential to “drive performance comparable to larger models at a lower cost”. This means private, secure AI for finance, healthcare, and every other enterprise vertical.
- And Mark Papermaster, the CTO and EVP at AMD the people literally building the chips for the next generation of “AI PCs” says Nanos represent a “powerful inflection point for AI PCs”. They’re building the hardware; Liquid AI is building the software. It’s a perfect match.
This is the dawn of the true AI PC and genuinely smart devices. We’re talking about cars that can assist the driver without needing a 5G connection, and apps that can summarize your meetings and draft your emails entirely offline on your laptop.
The economic ripple effect will be massive. Running AI on the edge drastically reduces or eliminates cloud inference costs, which are a major operational expense. This makes entirely new business models viable, especially for apps that need constant AI processing but can’t support high cloud bills. For big companies, it means deploying AI at scale without an exploding budget, all while keeping sensitive data behind their own firewall.
Liquid Nanos FAQ
What are Liquid Nanos, in plain English?
Tiny, task-specific LLMs (≈350M–2.6B params) built on Liquid’s LFM2 family to run on-device with frontier-grade results on core agent tasks like extraction, translation, RAG, tools, and math.
Do they actually run on phones and laptops with no cloud?
Yes. Liquid positions Nanos for phones, laptops, cars, and embedded devices zero cloud dependency and shows them in GGUF for llama.cpp, confirming CPU-friendly local runs.
How big are these models and how much memory do they need?
The launch set spans 350M → 2.6B parameters, with a stated ~100 MB to 2 GB RAM footprint depending on variant/quantization.
Are Nanos really “GPT-4o-class”?
Liquid’s press and independent coverage say Nanos hit GPT-4o-level performance on key, specialized tasks not a blanket claim across everything creative. Treat it as “near-frontier on targeted workloads.”
What’s shipping today what tasks are covered?
Initial models include Extract (multilingual JSON/XML/YAML), EN↔JP translation, RAG, Tool-use/function calling, and Math the building blocks of on-device agents.
How do I run a Nano locally with Transformers?
Pull the model from the LiquidAI org on Hugging Face and load with AutoModelForCausalLM/AutoTokenizer. Use the model card’s sampling notes for best results.
Can I run them on CPU via llama.cpp (GGUF)?
Yes Liquid (and community) provide GGUF builds; the local-LLM community has llama.cpp support threads, and you can track issues/updates in ggml-org.
Are there vision-language (multimodal) Liquid models too?
Yes. LFM2-VL (450M–1.6B) targets on-device VLM use; quantized GGUF checkpoints are available.
What makes LFM2 fast and small compared to typical Transformers?
LFM2 is a hybrid: short-range convolution blocks + grouped-query attention, with research notes highlighting Linear Input-Varying (LIV) operators and an automated architecture search (“STAR”). Net effect: strong quality with low memory and high throughput on edge hardware.
Why is on-device important for privacy?
Because inference happens locally; your personal context (docs, emails, messages) doesn’t need to leave the device to personalize the assistant. That’s the core pitch of Liquid’s “edge-native” stack.
Any credible enterprise or silicon endorsements?
Yes, public quotes from AMD (Mark Papermaster) and partner write-ups; Reuters also reported AMD leading a $250M round into Liquid AI.
How do these compare to popular small models like Qwen or Gemma?
Liquid’s material and coverage position Nanos as smaller/faster yet competitive on targeted tasks (extraction, translation, tool use). Treat head-to-head performance as task-dependent and verify on your own data.
Where do I get the models and docs?
Hugging Face LiquidAI collection for models; Liquid’s Nanos blog for task breakdown; LEAP site for SDKs, samples, and deployment flows.
Can I deploy to iOS/Android quickly?
Yes, LEAP is OS- and model-agnostic with mobile SDK samples to ship on-device LLMs in a few lines.
What does practical starter use cases?
- Invoices → JSON with Extract
- Offline EN↔JP travel translator
- On-device RAG for your files
- Tool-calling agents for calendar/home
All are covered by current Nanos and example cards. (Always benchmark on your real docs/devices.)
Any “gotchas” before I migrate workloads?
Check device RAM, quantization level (e.g., Q4_K_M vs Q6… in GGUF), and runtime (Transformers vs vLLM vs llama.cpp). Track llama.cpp issues for parallel/KV-cache edge cases as they get patched.
Final Verdict & Your Turn to Build!
So there you have it. Liquid Nanos. They’re not just a small step; they’re a giant leap. They’re proof that the future of AI isn’t just in the cloud; it’s in your hand, on your desk, and in your car. It’s fast, it’s powerful, it’s private, and it’s HERE. NOW.
The era of waiting for a server response is ending. The era of truly personal, responsive, and secure AI is beginning.
What are you waiting for? Go build the future!
- Check out the models on Hugging Face NOW: https://huggingface.co/collections/LiquidAI/liquid-nanos-68b98d898414dd94d4d5f99a
- Explore the full LEAP Platform: https://leap.liquid.ai/models
Drop a comment below and tell me what you’re going to build with these Nanos. The craziest idea gets a shoutout! Now go, build something amazing.












{kind=link}