
An exhaustive, hands-on review of Zhipu AI’s GLM-4.6. We break down its advanced agentic, reasoning, and coding skills, benchmark it against Claude Sonnet 4.5 and DeepSeek, and give you copy-paste code to get started. Is it the new open-weight king? Let’s find out.
The Hype is REAL: Zhipu Just Dropped a BOMB
ALRIGHT, FAM! Stop what you’re doing. Drop that pull request. Zhipu AI just casually dropped GLM-4.6, and the AI world is officially on notice. Another week, another model, right? WRONG. This isn’t just another incremental update to fill a changelog. This is a direct shot at the top dogs, and it’s packing some serious heat. So, grab your chai, because we’re about to break down if this new contender has what it takes to dethrone the likes of Claude and DeepSeek.
So, what is GLM-4.6 and why should you care? It’s the latest flagship model from Zhipu AI (now styling themselves as Z.ai), building on the solid foundation of GLM-4.5. For a busy dev, here’s the TL;DR: it’s an open-weight beast laser-focused on three things that actually matter: smarter agents, sharper reasoning, and, most importantly, god-tier coding assistance. It’s already live on their API, and the weights are coming to Hugging Face, so you can run it on your own metal.
This release isn’t just a new model; it’s a statement. Zhipu is gunning for the title of the most practical, powerful, and accessible state-of-the-art (SOTA) model for developers. They’re not just playing the benchmark game; they’re playing the real-world usability game. And here’s the most interesting part: Zhipu is being brutally honest. In their own announcement, they state that GLM-4.6 “still lags behind Claude Sonnet 4.5 in coding ability”. Some might see that as weakness. I see it as a GIGA-CHAD move. They’re not trying to win a meaningless benchmark war; they’re trying to win the war for your workflow. The LLM market is no longer a single race to the top; it’s fragmenting into specialized roles. By being transparent, Zhipu is building trust with developers who are sick of overblown marketing hype. Their real play isn’t to be the “best” model, but to be the “best overall value proposition” for developers. It’s the pragmatic choice: powerful enough for 99% of tasks, but without the vendor lock-in, high costs, or closed-source limitations of competitors.
The Spec Sheet: GLM-4.6 By The Numbers (The Juicy Bits)
Okay, let’s pop the hood. No marketing fluff, just the raw specs that make this thing tick. This is the stuff you’ll be bragging about on Twitter.
- Architecture: It’s a 355B total parameter model running a Mixture-of-Experts (MoE) design. Quick explainer for those in the back: MoE means it’s super-efficient. It only uses a fraction of those parameters about 32B active ones for any given token, saving you compute and cash.
- Context Window: A WHOPPING 200K tokens for input! That’s a massive jump from 128K in GLM-4.5. We’ll get into what this means practically, but spoiler: you can feed it your entire messy codebase without breaking a sweat.
- Max Output: A generous 128K tokens. It can practically write a whole application for you in a single go.
- License: The Hugging Face model card lists it with an MIT License. This is a HUGE win for the open-source community. It means you can use it, modify it, and deploy it pretty much however you want.
- Availability: It’s ready to roll via the Z.ai API and OpenRouter. Plus, the weights are dropping on HuggingFace and ModelScope, so you can get it running locally.
To put it in perspective, here’s how it stacks up against its older brother.
| Feature | GLM-4.5 | GLM-4.6 (The Upgrade!) | Why It Matters |
| Context Window | 128K Tokens | 200K Tokens | More context for complex agentic tasks & large codebases. |
| Performance | Strong Baseline | Clear Gains (Reasoning, Coding, Agents) | Better real-world results, fewer errors. |
| Token Efficiency | Baseline | ~15% More Efficient | Lower API costs, faster task completion. |
| Focus | General Purpose Agent | Advanced Agentic & Coding | Laser-focused on developer workflows. |
The BENCHMARKS DON’T LIE (mostly 😉): Crushing the Leaderboards
Time for the main event. How does GLM-4.6 actually stack up when you put it to the test? Zhipu dropped a whole bunch of benchmark scores, so let’s cut through the noise and see what these numbers really mean for you, the developer.
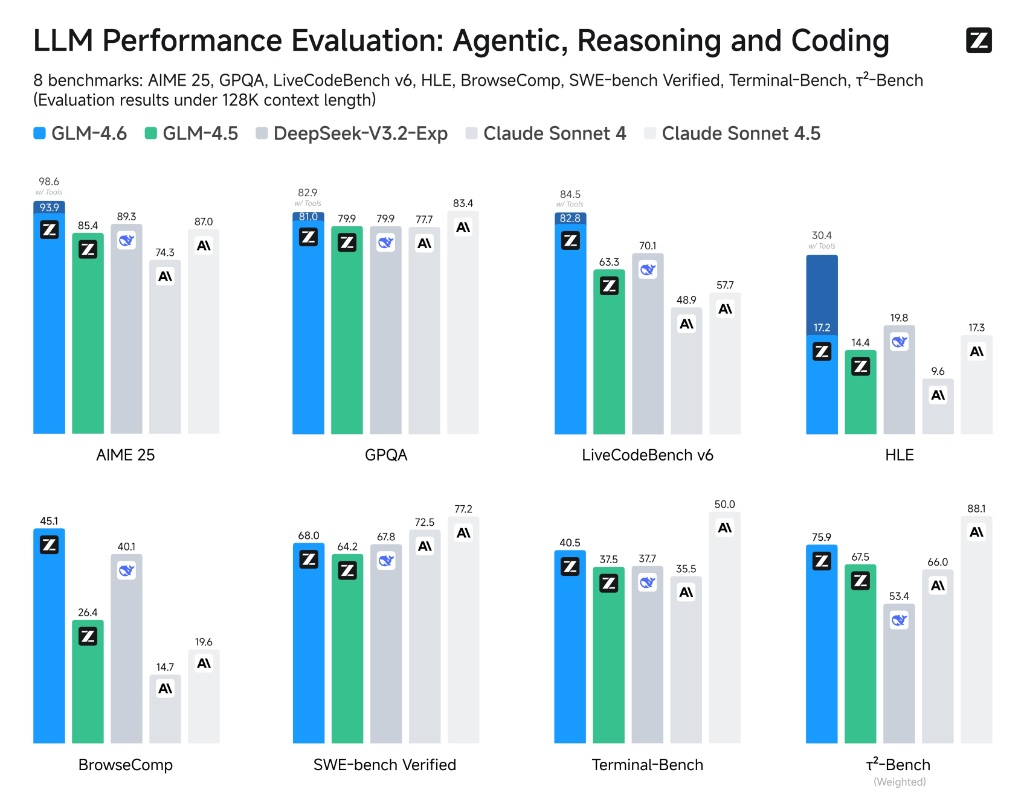
The official benchmark results from Z.ai. GLM-4.6 (in blue) is showing some serious muscle across the board. Let’s break it down.
- AIME 25 & GPQA (Reasoning): Look at that AIME 25 score: 98.6! That’s basically top of the class, neck-and-neck with the best models out there. The GPQA score of 82.9 is also elite. This means for complex problem-solving, deep thinking, and logical deduction, this model has a seriously big brain.
- SWE-Bench Verified (Coding): Okay, the big one for us coders. A score of 68.0. It’s a solid jump from GLM-4.5 (64.2) and it’s right there in the same league as DeepSeek-V3.2-Exp (67.8). But, as Zhipu themselves admit, Claude Sonnet 4.5 is still the king of this particular hill at 72.5. This tells us it’s a very, very competent coder, but maybe not the absolute number one for pure, hardcore algorithm challenges.
- LiveCodeBench v6 & Terminal-Bench (More Coding & Tool Use): On LiveCodeBench, it hits an incredible 82.8, absolutely smoking its predecessor and even beating Claude Sonnet 4. This is HUGE. This benchmark tests multi-turn coding problems, which is much closer to how we actually work day-to-day. On Terminal-Bench, a score of 40.5 shows its solid ability to use command-line tools, a direct measure of its agentic skills.
The overall takeaway from the charts is clear: GLM-4.6 is a massive improvement over 4.5 and a top-tier contender across the board. It’s not a clean sweep on every single test, but it’s consistently at or near the top, especially in reasoning and practical, multi-step coding tasks.
Real-World Gauntlet: Agentic Coding on CC-Bench
Benchmarks are like gym numbers. Impressive, but can you play the sport? Zhipu knows this, so they tested GLM-4.6 on something called CC-Bench, which is basically a real-world developer simulation. No multiple-choice questions here, just pure, multi-turn coding tasks like front-end development, tool building, and data analysis evaluated by humans in an isolated Docker environment.THIS is where it gets interesting.
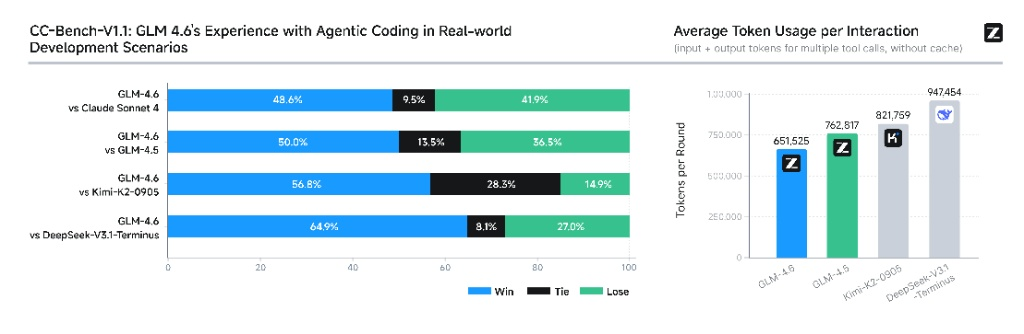
Real-world performance on CC-Bench and token usage. The win/loss/tie bars tell a story, and so does that token efficiency chart.
- vs. Claude Sonnet 4: Look at that first bar. A 48.6%-win rate against Claude Sonnet 4. In the real world, that’s what we call ‘near parity’. It means in a head-to-head coding session, it’s basically a coin toss who performs better. For an open-weight model to achieve this against a closed-source giant is INSANE.
- vs. Other Open Models: It absolutely demolishes other open-source models like Kimi-k2-0905 (56.8%-win rate) and DeepSeek-V3.1-Terminus (64.9%-win rate). This firmly establishes it as the new leader of the open-source pack in practical, real-world coding scenarios.
The Efficiency Angle – DOING MORE WITH LESS
Now, look at the chart on the right. That’s the average token usage per interaction. GLM-4.6 uses 651,525 tokens per round. Compare that to its predecessor, GLM-4.5, which burned through 762,817 tokens. That’s a ~15% reduction in token usage to get the same job done!3 What does this mean for you?
LOWER API BILLS! And faster responses. It’s not just smarter; it’s more efficient. This is a massive W.
Zhipu is making a very smart play here. They are heavily promoting these “real-world” results, even publishing the agent trajectories for transparency. They explicitly say, “Real-world experience matters more than leaderboards”. The developer community is getting tired of standard benchmarks that can be gamed. By championing a practical test like CC-Bench, Zhipu is aligning with developer sentiment and building credibility. They are changing the narrative from “who has the highest score?” to “who provides the most value in a real-world workflow?”. It’s a sophisticated strategy that positions GLM-4.6 as the pragmatic developer’s choice, appealing to both performance needs and budget constraints.
ENOUGH TALK, LET’S CODE: Getting Your Hands Dirty with GLM-4.6
Theory is great, but we’re builders. Let’s get this thing running. I’m going to give you the copy-paste-ready commands to get started in minutes. No fluff, just code. Let’s GO! 🔥
The Easy Way: API Access (Instant Gratification)
Want to try it RIGHT NOW? The API is the fastest way. Zhipu has its own endpoints, but my favorite way is through OpenRouter because it normalizes everything, and you can switch between models easily.
Using the Z.ai API (Python requests)
Here’s the raw Python way to hit their official endpoint. Just swap in your API key and you’re good to go.
import requests
import json
# Set your API Key
# Make sure to replace 'YOUR_API_KEY' with your actual key
headers = {
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
}
# Define the API endpoint
url = "https://open.bigmodel.cn/api/paas/v4/chat/completions"
# Prepare the data payload
data = {
"model": "glm-4.6", # Specify the model
"messages":
}
# Send the POST request
try:
resp = requests.post(url, headers=headers, json=data)
resp.raise_for_status() # Raises an HTTPError for bad responses (4xx or 5xx)
print(resp.json())
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")Using OpenRouter (OpenAI SDK)
If you’re already using the OpenAI Python library (and who isn’t?), you can switch to GLM-4.6 with just a few lines of code. This is my preferred method for quick tests.
import openai
client = openai.OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="YOUR_OPENROUTER_KEY",
)
completion = client.chat.completions.create(
model="z-ai/glm-4.6", # The magic happens here
messages=,
)
print(completion.choices.message.content)The Pro Move: Local Deployment with vLLM
Alright, for the real ones who want to run this on their own metal. Open weights mean freedom! The model weights are on Hugging Face. The best way to run this beast for that sweet, sweet inference speed is with vLLM.
Step-by-Step Commands:
- First, install vLLM if you haven’t already.
pip install vllm - Now, run the API server. This command will download the model from Hugging Face (
zai-org/GLM-4.6) and spin it up. The--tensor-parallel-sizeflag splits the model across multiple GPUs. Adjust it based on your setup.python -m vllm.entrypoints.api_server \ --model zai-org/GLM-4.6 \ --tensor-parallel-size 2
A quick warning: this is a 355B parameter model. You’ll need some serious VRAM or a quantized version to run it locally. The community is already buzzing about GGUF and other quants, so keep an eye out on Hugging Face and the r/LocalLLaMA subreddit!
Supercharge Your Workflow: Integrating with Coding Agents
This is the killer feature. GLM-4.6 is built to be the brain of your favorite coding agent, like Claude Code, Cline, Roo Code, and more. And upgrading is ridiculously easy.
If you’re a Claude Code user with a GLM Coding Plan subscription, you’re probably already upgraded. If you have a custom config, it’s a one-line change.
- Open your
~/.claude/settings.jsonfile. - Find the model key and just change it:
{ "ANTHROPIC_DEFAULT_OPUS_MODEL": "glm-4.6", "ANTHROPIC_DEFAULT_SONNET_MODEL": "glm-4.6", "ANTHROPIC_DEFAULT_HAIKU_MODEL": "glm-4.5-air" }
That’s it. You’re done. You’re now coding with GLM-4.6. SO. EASY.
The Agentic Dream: How It Uses Tools
Okay, so what does ‘agentic’ actually mean in code? It means the model can decide to call functions (tools) to get more info or perform actions. Think of it running a search, executing code, or calling another API to get data.
While Zhipu’s docs are a bit light on a direct, copy-paste Python example for tool use, the principle is similar to OpenAI’s function calling. The model itself decides when to call a tool, runs it, gets the result back, and then continues its reasoning. Here’s a conceptual example:
You ask: “Generate a Python script for a 3D scatter plot where the color depends on the Z-axis.”
GLM-4.6’s Internal Thought Process:
- “Okay, I’ll generate the initial Matplotlib code.”
- “Wait, let me be sure this runs. ****”
- “Tool returned an error:
missing cmap parameter.” - “Ah, my bad. Let me fix the code by adding
cmap='viridis'.” - “****”
- “Success! Now I can give the user the final, working code.”
You get back the final, tested, and correct code:
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
# Generate random data
x = np.random.rand(100)
y = np.random.rand(100)
z = np.random.rand(100)
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# Create the scatter plot, mapping color to the z-axis
sc = ax.scatter(x, y, z, c=z, cmap='viridis')
# Add a color bar to show the mapping
plt.colorbar(sc)
plt.show()See? It’s not just a code generator; it’s a code debugger. That’s the agentic difference.
The Final Showdown: GLM-4.6 vs. The World
So we’ve seen the specs, the benchmarks, and the code. Now for the ultimate question: how does it feel? Where does it fit in your stack? Let’s put it head-to-head with the other titans.
GLM-4.6 vs. Claude Sonnet 4.5
- The Coding Battle: Let’s be upfront. For raw, complex, algorithmic coding and deep security analysis, Sonnet 4.5 seems to still have the edge. It’s a technical beast. However, for front-end development, generating “visually polished” pages, and multi-turn collaboration, GLM-4.6 is right there with it. Some users even feel it’s less ‘opinionated’ in its design choices, giving you more direct and functional code.
- The Context & Cost Battle: GLM-4.6 has a 200K context window. Sonnet 4.5 has a 1M context window. Sonnet wins on raw size, but let’s be honest, 200K is more than enough for 99% of projects. And the cost? It’s not even a competition. GLM-4.6 via the coding plan (starting at $3/month) is a fraction of the price of Sonnet 4.5’s API, which runs at $3/M input and $15/M output tokens.
- Verdict: Use Sonnet 4.5 when you need the absolute best-in-class for a critical, complex backend or security task. Use GLM-4.6 for 80% of your daily driving: front-end, agentic workflows, and anything where budget and the freedom of open-weights matter.
GLM-4.6 vs. DeepSeek-V3.2-Exp
- The Open-Weight Championship: This is the true battle of the open-weight giants. On benchmarks, they are incredibly close, trading blows here and there. DeepSeek has its fancy DeepSeek Sparse Attention (DSA) for long-context efficiency, but GLM-4.6’s strong real-world CC-Bench results give it a slight edge in practical, multi-turn coding tasks.
- Verdict: This is a tough one and might come down to personal preference and specific use cases. Right now, GLM-4.6 feels slightly more polished and geared towards agentic tasks out of the box. But both are incredible options for anyone committed to the open-source ecosystem. My advice? Try both!
GLM-4.6 vs. GLM-4.5
- Is the Upgrade Worth It? YES. 100%. No question. You get a larger context window, better performance across the board, and it’s more token-efficient. It’s a straight upgrade in every way that matters. If you’re using 4.5, switch to 4.6 today.Here’s a tight, SEO-friendly FAQ you can drop into your post. I’ve pulled the questions from what folks are actually asking on Google/Reddit/Quora, and I’m answering in a crisp, practitioner voice no fluff.
GLM-4.6: Frequently Asked Questions (Real Questions, Straight Answers)
Q1) What’s new in GLM-4.6 vs GLM-4.5?
Bigger 200K context, stronger real-world (agentic) coding, better reasoning, and leaner token usage. Zhipu’s own data also says it still trails Claude Sonnet 4.5 on some pure coding evals refreshingly honest.
Q2) How big is the context window and can it really output long code?
Official docs list 200K input and 128K max output tokens. That’s plenty for large repos and multi-file refactors.
Q3) Is GLM-4.6 open-weight and what’s the license?
Yes weights are up on Hugging Face under MIT license; the card lists ~357B params (MoE). Great for self-hosting and customization.
Q4) Where can I use it right now (and what does it cost)?
Two easy paths: Z.ai API (official) and OpenRouter. On OpenRouter, the listing shows ~200K context and pricing around $0.60/M input, $2/M output at launch.
Q5) How does it stack up against Claude (Sonnet 4 / 4.5) in practice?
Zhipu reports near-parity with Claude Sonnet 4 on its CC-Bench real-world coding tests, but also notes Claude Sonnet 4.5 still leads on coding ability. That matches community chatter: strong, but Claude still edges tough security/algorithmic tasks.


Q6) What is CC-Bench and why should I care?
It’s a human-judged, multi-turn “agentic coding” gauntlet run in Docker (front-end builds, tool creation, data analysis, testing, algorithms). GLM-4.6 posts a 48.6% win rate vs Claude Sonnet 4 and uses ~15% fewer tokens than 4.5 to finish tasks so better outcomes and lower token burn.
Q7) Can I self-host GLM-4.6 with vLLM or SGLang?
Yes. Zhipu says GLM-4.6 supports vLLM and SGLang, and weights are on Hugging Face and ModelScope. (Community quants like 4-bit MLX are already popping up for lighter hardware.)
Q8) Does GLM-4.6 actually feel cheaper to run?
For API use: OpenRouter pricing is competitive. For agents: Zhipu claims ~15–30% token savings vs GLM-4.5 in its evals, which tracks with lower bill shock on long sessions. (Your mileage depends on prompts/tools.)
Q9) Is GLM-4.6 better than DeepSeek for open-weight dev work?
They trade blows on different benches; Zhipu’s post shows advantages over DeepSeek-V3.2-Exp in places, with a clear “real-world coding” push. My take: try both your stack, tools, and prompts decide the winner.
Q10) Which agent tools and IDE flows does it play nice with?
Zhipu explicitly calls out Claude Code, Roo Code, Cline, Kilo Code and more. If you’ve hard-coded a Claude model name in config, you can just swap to "glm-4.6" and go.
Q11) Is GLM-4.6 a “Claude killer”?
For price-to-performance, openness, and agent workflows it’s the people’s champ. For absolute edge-case coding depth, Claude Sonnet 4.5 still holds an edge right now. Pick based on workload, not vibes.
Q12) Where do I find official specs, code samples, and the benchmark data?
Start with the GLM-4.6 blog and developer docs for features and API snippets; check OpenRouter for model/pricing; grab weights on Hugging Face; and see CC-Bench trajectories on HF for transparency.
Q13) What’s the parameter story how “big” is it really?
The HF card lists ~357B parameters (MoE). MoE means most experts stay idle per token, keeping compute manageable while scaling capacity handy for long-context agent work.
14) Any gotchas before switching my whole team?
Two: (1) Benchmarks ≠ your stack run your own multi-turn tasks before committing. (2) Ecosystem maturity Claude’s tooling is very mature; GLM-4.6 is catching up fast, but pilot first.
The Verdict: So, Should You Switch? 👑
We’ve been through a lot. The hype, the numbers, the code. So what’s the final word on GLM-4.6? It’s a MONSTER. It’s not the undisputed king of everything, but it might just be the people’s champion.
This model is PERFECT for:
- The Pragmatic Developer: You want SOTA-level performance for coding and agentic tasks but are tired of paying exorbitant API fees from the big players.
- The AI Innovator: You want to build complex, multi-step agents that need a large context window and the freedom of local deployment to fine-tune and experiment.
- The Open-Source Advocate: You believe in the power of open weights and want to run, modify, and own your stack without being locked into a big tech ecosystem.
Who should maybe stick with something else?
- The Absolute Performance Chaser: If your entire business depends on squeezing out that last 0.5% of accuracy on a hyper-complex security or algorithmic task, the extra cost for Sonnet 4.5 might still be justified for you.
The Bottom Line: GLM-4.6 is a landmark release. It democratizes access to elite agentic and coding capabilities. It’s powerful, efficient, surprisingly affordable, and open. Zhipu AI didn’t just release a new model; they released a new standard for what a top-tier open-weight model should be. It’s not just a Claude-killer; it’s a complexity-killer and a budget-saver. And for that, it deserves a spot in every serious developer’s toolkit.












{kind=link}