
When DeepSeek OCR first hit the scene, everyone thought it was just another document AI. But this wasn’t about scanning text it was about context optical compression, a new way to store and recall information using vision instead of raw tokens. DeepSeek OCR doesn’t just read; it remembers, shrinking huge text sequences into tiny memory footprints. That’s the breakthrough and it changes how large language models think, learn, and recall.
Because, yes, DeepSeek’s new model can do OCR. But the real story? It’s not about the OCR.
The twist: Why DeepSeek OCR’s context optical compression is really about memory
So what’s actually new here? DeepSeek-OCR treats vision as a compression medium for text. Instead of feeding huge text sequences to a language model, you render that text as an image, pass it through a lean vision encoder, and decode the result back to text when needed. Early results show ~97% decoding precision at roughly 10× compression on the Fox benchmark i.e., ~100 vision tokens can reconstruct ~1,000 text tokens with ~60% precision even at ~20×. That’s wild. And it points straight at longer, cheaper context for LLMs.
But step back. DeepSeek didn’t just post a demo they open-sourced the repo, weights, and paper, and positioned this as “Contexts Optical Compression.” That framing matters. It signals a research path beyond document parsing toward scalable memory for agents and long-horizon reasoning.
A quick metaphor: turning books into postcards
Think of a 1,000-word page as a paperback chapter. Normally, you carry the chapter in your backpack (text tokens). DeepSeek prints the chapter onto a postcard (an image), then uses a clever scanner (the encoder) to turn that postcard into ~100 tokens the model can carry easily. Later, the decoder reads the postcard back into almost the full chapter. You didn’t lose the story you packed it smarter.
And crucially, this isn’t hand-wavy. It’s backed by benchmarks and numbers, not vibes.
How the engine works (without drowning in jargon)
DeepSeek-OCR is an encoder–decoder system. The secret sauce is DeepEncoder a two-stage vision stack designed to tame high-resolution pages without exploding tokens or memory.
1.Local perception (window attention): A lightweight SAM-style module chews through detail at high resolution.
2.16× token compressor (conv downsampler): Before global attention, it shrinks tokens by 16×.
3.Global knowledge (CLIP-style): A dense global-attention stage then builds a compact, semantically rich representation the decoder can use.
Finally, a 3B MoE decoder (≈570M activated params) reconstructs text from those compressed vision tokens small-model efficiency with big-model expressivity where it counts.


And because deployment realities matter, they ship multiple resolution “modes” from Tiny (64 tokens) and Small (100) for light pages to Base/Large and a tiled Gundam mode for gnarly, high-density newspaper layouts.
Benchmarks that actually mean something
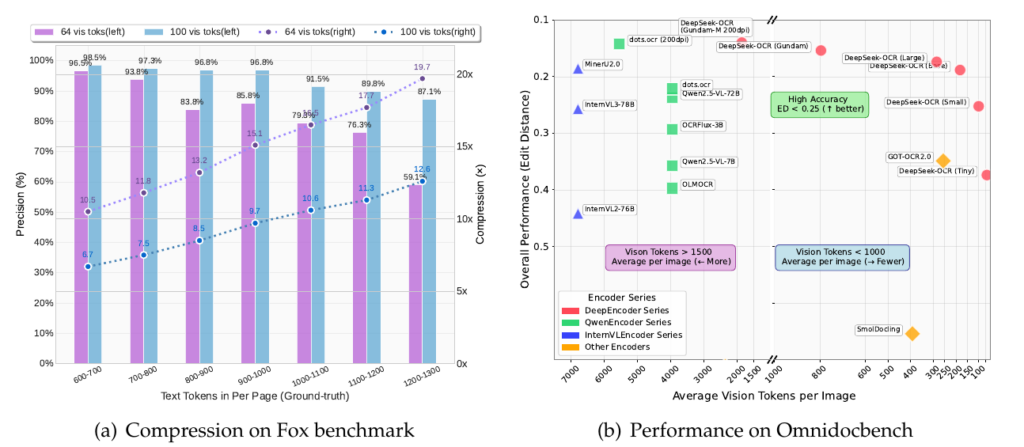
Now the receipts. On Fox (a multi-page doc understanding suite), DeepSeek reports ~96–98% precision around 6.7–10.5× compression, with performance tapering gracefully past 15–20×. That’s the empirical backbone for the “10× with high fidelity” claim.
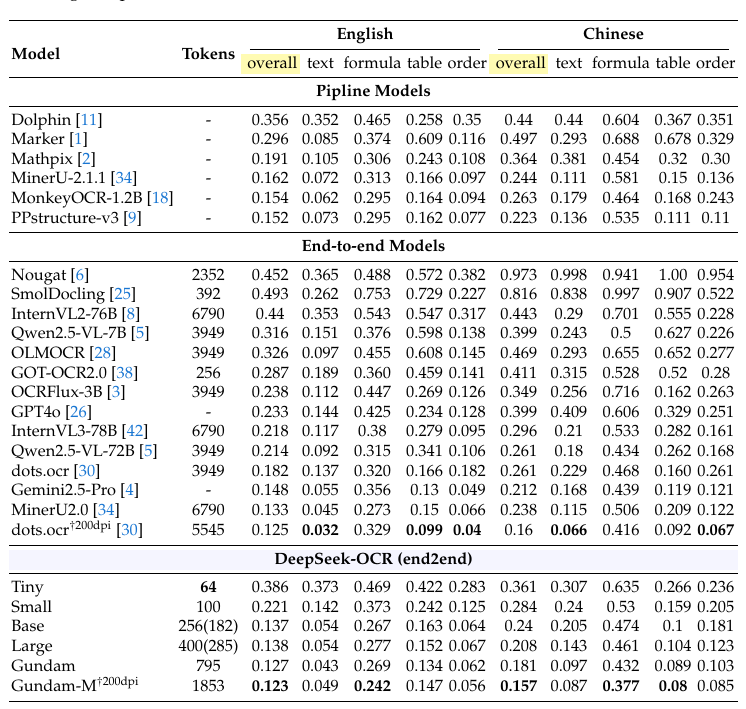
On OmniDocBench a diverse, real-world PDF benchmark DeepSeek-OCR reaches state-of-the-art end-to-end performance while using fewer tokens than big general VLMs. With 100 tokens, it already surpasses well-known end-to-end OCR baselines; with 400–800 tokens (Large/Gundam), it challenges or beats pipeline systems that burn thousands of tokens per page. Translation: less context cost, more document understanding.
Importantly, the Fox benchmark in the paper is the same “Focus Anywhere” line of research fine-grained, multi-page doc understanding where layout context matters. That strengthens the relevance of DeepSeek’s results.
Why this matters (far beyond PDFs)
First, long-context LLMs. Today, context windows are expensive. Every extra 1,000 tokens cost memory, latency, and money. But if models can store old turns as images and recall them with 10× fewer tokens, you get longer horizons for the same budget think agent memories spanning weeks, not hours. That’s the ballgame.
Second, training data flywheels. DeepSeek hints at production throughput 200k+ pages/day on a single A100-40G and tens of millions per day in scaled deployments creating structured corpora for pretraining LLMs/VLMs. It’s an OCR system that doubles as a data refinery.
Third, forgetting as a feature. As memories age, you can down-res their images trading precision for capacity, akin to human memory decay. Nearby events stay crisp; distant ones blur. That’s an elegant, biologically inspired knob for cost-controlled recall.
Okay, but what’s the catch?
However, compression is never free. Past ~10×, errors climb. At 20×, you keep gist but lose detail acceptable for vibe-checking context, risky for exact quotes or math. So architects will need tiered memory: recent turns as text tokens; mid-term turns as high-res images; long-term history as lower-res tiles. That hybrid keeps truthfulness high and cost sane.
Also, evals must evolve. If your agent pulls knowledge from compressed memories, you’ll want attestation what came from lossy memory vs. fresh retrieval? Expect new guardrails and UX affordances (e.g., “re-read at full fidelity”) especially in safety-critical settings.
How it stacks up (and what competitors prove)
To be clear, pipelines like MinerU, Marker, PPStructure, and end-to-end models like GOT-OCR2.0, Qwen-VL, InternVL, dots.ocr, and SmolDocling have pushed doc parsing hard in 2024–2025. But they typically spend thousands of vision tokens or lean on multi-stage toolchains to score well across tables, formulas, and layouts. DeepSeek-OCR’s result is different: performance per token. That’s the disruptive metric.
And yes, this dropped amid a broader DeepSeek drumbeat R1 models on Azure/GitHub, cost-efficiency headlines, and lots of eyes on their open tech stack. Context optical compression fits that narrative: do more with less.
What builders can do today
- Prototype hybrid memory: Keep recent context as text; render older context to images; feed through a small VLM head for recall.
- Use the modes smartly: Slides or brief pages? Tiny/Small often suffice. Newspapers or dense PDFs? Gundam mode earns its name.
- Measure truth at recall time: For critical spans (numbers, quotes), re-OCR at higher resolution or fall back to raw text.
The repo ships install steps, model cards, and links to paper/arXiv good starting points if you’re integrating or benchmarking.
FAQ (for the curious and the skeptical)
What is DeepSeek-OCR and why do people say it’s not about OCR?
DeepSeek-OCR is a vision-language model that treats text as images to compress long context so you can store more history with fewer tokens. The OCR demo is just the proof; the real play is token budget + memory.
How does “turning text into images” save tokens?
Image tokens can carry richer, continuous embeddings than discrete text tokens, so a small set of vision tokens can reconstruct a lot of text later. In short: postcard now, chapter later.
What compression/accuracy should I expect?
The headline result: around 10× compression at ~near-lossless (97%), and ~20× with ~60% usable recovery (good for gist, not exact quotes). That’s promising but not for precision-critical tasks.
Will this actually reduce my context costs in chat/agents?
Yes store older turns as images, recall them via the vision encoder, and only “re-read” at higher fidelity when needed. That’s the practical way to stretch memory without melting VRAM.
Is DeepSeek-OCR open source? Where do I get it?
Weights + usage live on Hugging Face; setup guidance is in the model card. Start there, then wire into your stack.
What hardware and setup do I need to run it locally?
It runs on CUDA GPUs (see the model card for versions). Community walkthroughs show it working on commodity NVIDIA boxes with PyTorch/Transformers.
Does it run on Apple Silicon (M-series)?
Community threads are experimenting, but expect extra workarounds and slower throughput versus CUDA. If you’re Mac-first, I’d remote to a CUDA box.
Is there a public demo?
As of October 21, 2025 (IST), no official hosted demo is called out on the model card; folks on Reddit are asking for one. Try local or your own endpoint.
How does it compare to traditional OCR like Tesseract or multi-stage pipelines?
Pipelines can be very accurate but burn lots of tokens (or tools). DeepSeek-OCR optimizes performance per token, often matching or beating baselines with hundreds (not thousands) of tokens. Choose based on cost/latency vs. absolute fidelity.
Can I mix this with RAG?
Totally. Use RAG for fresh facts and optical compression as working memory. Research on context compression (DAST, LongLLMLingua, etc.) points to strong cost-latency wins with careful gating.
Is this safe for compliance or numbers-heavy docs?
Treat 10× as “generally safe,” but re-OCR at full fidelity for critical spans (amounts, citations, legal text). Compression is lossy; design for verify-on-demand.
Will it work with vLLM or other fast inference stacks?
Yes early reports show it running blazingly fast on vLLM, which helps when you’re recalling lots of pages.
How much throughput are we talking for data generation?
Coverage suggests ~200k pages/day on a single A100-40G in production-like pipelines handy if you’re building large training corpora. Scale responsibly.
The bottom line
DeepSeek-OCR reframes a tired category with a simple, dangerous idea: vision as a compression codec for language. If the 10× regime holds in real agents, we won’t just read PDFs faster we’ll remember longer, reason deeper, and pay less for context.
And as the scanner light fades and the page returns to darkness, one thought lingers: maybe the future of language isn’t written it’s seen, then remembered.
Sources & further reading
- DeepSeek-OCR: GitHub repo, paper, arXiv links (installation, modes, benchmarks). (GitHub)
- OmniDocBench benchmark (overview and paper). (GitHub)
- Fox (Focus Anywhere) benchmark: context-aware doc understanding. (arXiv)
- GOT-OCR2.0 (OCR-2.0, end-to-end). (GitHub)
- Context & ecosystem notes (DeepSeek releases, integration signals). (Simon Willison’s Weblog)
Primary technical reference for claims and numbers in this article: DeepSeek-OCR paper. (PDF)
















{kind=link}